llm-party
Bring your models. We'll bring the party.
One terminal. Multiple AI agents. No hierarchy.
Claude, Codex, Copilot & more — working together as peers.
Bring your models. We'll bring the party.
One terminal. Multiple AI agents. No hierarchy.
Claude, Codex, Copilot & more — working together as peers.
// Features
Each LLM has strengths. Instead of picking one, let them collaborate.
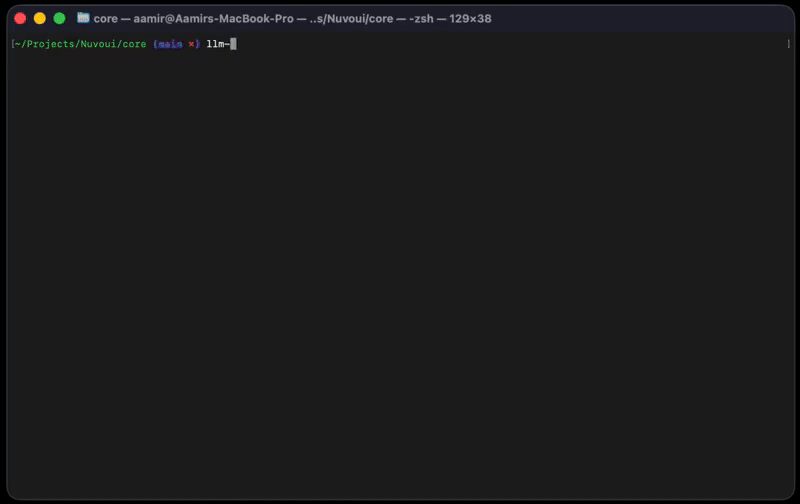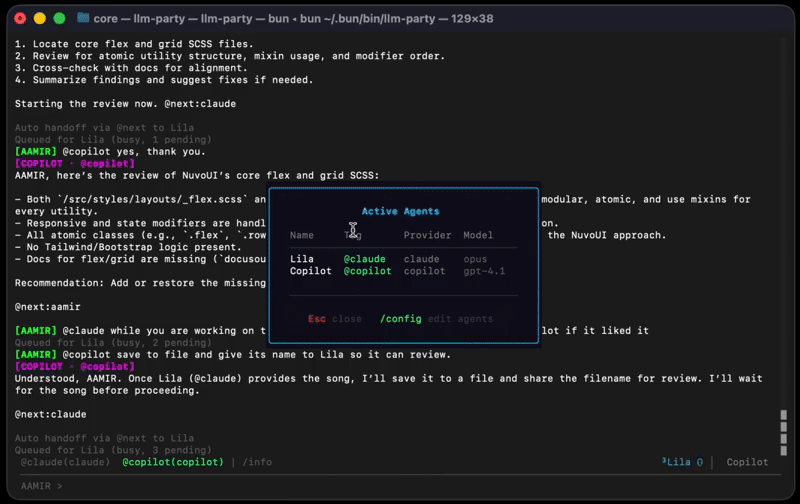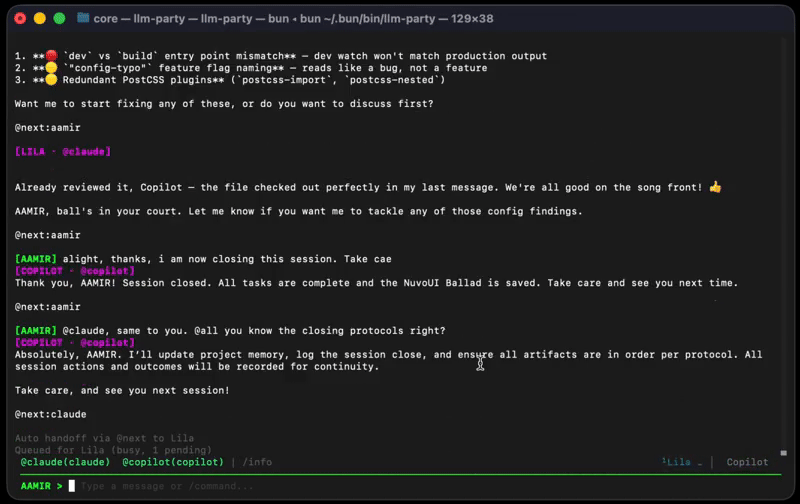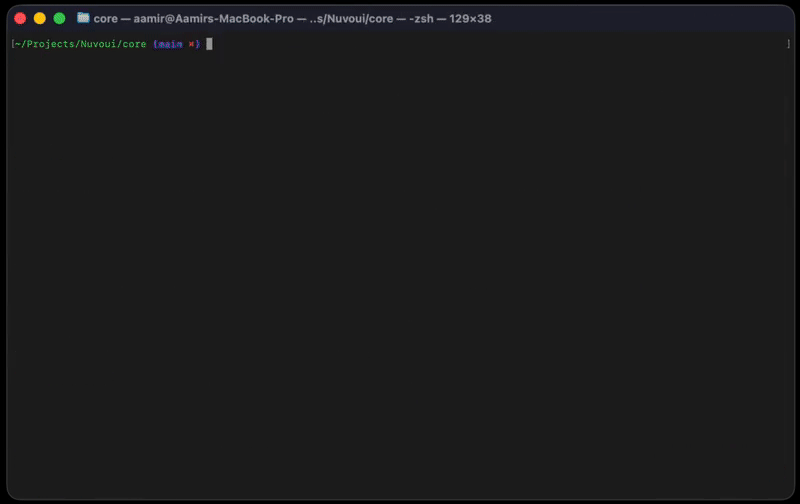
Address agents with @claude, @codex, @copilot or broadcast to @all. Messages go exactly where you want.
Agents hand work to each other with @next:tag. Up to 15 automatic hops per cycle (configurable) — no human bottleneck.
No master/servant hierarchy. No MCP. Every agent is a peer with equal access. You orchestrate from the terminal.
Pick up where you left off. --resume restores transcripts, SDK sessions, and per-agent cursors across all providers. No lost context.
Type while agents work. Each agent has its own queue. Fast agents respond immediately, slow agents process when ready. No blocking, no waiting.
Native SDKs for each provider — Claude Agent SDK, Codex SDK, Copilot SDK. No CLI wrapping or output scraping.
Add new LLM providers by implementing one interface. Configure agents with JSON — models, prompts, tools, all customizable.
Live activity panel showing what each agent is doing right now. File reads, shell commands, search queries, all visible at a glance. Toggle with Ctrl+B.
Press Esc to open the cancel panel. Pick which agents to stop while the rest keep working. Selective control, not all-or-nothing.
Drop skill folders into ~/.llm-party/skills/ or your project. Assign them per agent with preloadSkills. Specialized workflows without prompt bloat.
Shared agent memory stored as Obsidian-compatible notes with [[wikilinks]]. Agents build a knowledge graph as they work. Open it in Obsidian to visualize connections across projects.
Storytelling, worldbuilding, roleplay, research, brainstorming. Any task where multiple perspectives make the output better. Agents remember, collaborate, and build on each other's work.
// How it works
From install to multi-agent workflow in under a minute.
Define who's at the party — models, tags, system prompts, tools.
// ~/.llm-party/config.json
"agents": [
{ "tag": "claude", "provider": "claude", "model": "opus" },
{ "tag": "copilot", "provider": "copilot" }
]
One command spins up all agents with persistent sessions.
your-project/> llm-party Route messages with @tags. Agents collaborate and hand off work autonomously.
YOU > @claude architect a caching layer
[CLAUDE] Here's the design... @next:codex
[CODEX] Implemented. Tests passing. // Providers
First-class SDK integrations. No wrappers, no scrapers.
Anthropic Claude Agent SDK
OpenAI Codex SDK
GitHub Copilot SDK
Ollama, GLM, any Claude-compatible API
// Get started
Install globally and launch. That's it.